

В данном исследовании представлена экспериментальная платформа, интегрирующая компьютерное зрение и машинное обучение для поддержки приблизительной оценки pH и определения конечной точки в экспериментах по титрованию в рамках научного образования. Для захвата изображений раствора в реальном времени использовалась установка на базе Raspberry Pi, которые затем преобразовывались в данные RGB для анализа. Предварительная обработка изображений на основе сетки уменьшила артефакты, вызванные рябью и локальными цветовыми вариациями. Кластерный анализ выявил три категории растворов на основе RGB, коррелирующие с pH.
Регрессионный анализ, включая моделирование методом случайного леса, показал высокую точность прогнозирования с низкой погрешностью. Также были оценены модели классификации машинного обучения, при этом метод случайного леса и метод k-ближайших соседей продемонстрировали высокую эффективность для нелинейной зависимости между pH и значениями RGB. Результаты подтверждают целесообразность использования BTB в его диапазоне переходов для приблизительной оценки pH и определения конечной точки в образовательной среде.
Система также может использоваться в качестве образовательной платформы, с помощью которой студенты взаимодействуют с автоматизированным сбором данных, машинным обучением и анализом в реальном времени. За счет сокращения субъективного визуального наблюдения и повышения воспроизводимости экспериментов этот подход способствует использованию цифровых технологий в научном образовании.
1. Введение
Использование цифровых технологий в образовании расширилось на различные дисциплины и открыло новые возможности для лабораторных занятий [1, 2, 3]. В естественнонаучном образовании компьютерное зрение, искусственный интеллект и машинное обучение могут связать теоретические концепции и практические эксперименты, а также способствовать развитию вычислительного мышления. Эти технологии позволяют автоматизировать сбор данных, снизить зависимость от субъективного наблюдения и обеспечить обратную связь в режиме реального времени во время лабораторных работ.
Изменение цвета индикаторов — это фундаментальное понятие, широко используемое в различных научных областях, включая химию, нейробиологию и медицину. Индикаторы — это вещества, которые демонстрируют видимое изменение, часто изменение цвета, в ответ на определенные химические, биологические или физические условия. Это свойство делает их бесценными инструментами для обнаружения, измерения и визуализации различных аналитов или физиологических изменений. В химии индикаторы необходимы для качественного и количественного анализа. Они помогают обнаружить присутствие и концентрацию определенных ионов или молекул, демонстрируя отчетливое изменение цвета в ответ на химические реакции или изменения pH или окислительно-восстановительного потенциала [4]. В нейробиологии индикаторы играют важную роль в визуализации и измерении нейронной активности для изучения сложных функций мозга, а в медицине индикаторы облегчают диагностику, предоставляя визуальные сигналы, соответствующие физиологическим или биохимическим изменениям [5, 6].
Искусственный интеллект продвинул цифровую колориметрию, позволив количественно определять аналиты с помощью камер. В рабочих процессах на основе смартфонов и веб-камер модели машинного обучения обрабатывают изображения анализов, извлекают цветовые характеристики и сопоставляют их с концентрацией или pH с низкой погрешностью. Шумоподавление и нормализация освещения дополнительно повышают надежность [7, 8, 9, 10]. В смежных областях ИИ используется с помощью различных оптических механизмов. Например, в нейробиологии ИИ анализирует флуоресцентные репортеры, интенсивность или спектр которых изменяется в зависимости от активности, что позволяет автоматизировать сегментацию и вывод пиков, а не истинное колориметрическое изменение [11, 12, 13, 14].
В медицине приложения с поддержкой ИИ интерпретируют изображения тест-полосок для обеспечения быстрых результатов в домашних условиях в пределах проверенных диапазонов [15 16]. Помимо этих областей, машинное зрение на основе цвета в сочетании с машинным обучением «белого ящика» также применялось для оценки качества пищевых продуктов, демонстрируя широкую применимость анализа цвета на основе камер [17].
Недавние исследования по автоматизированному мониторингу титрования показали, что компьютерное зрение может быть использовано для определения конечной точки и оценки pH. Боппана и др. [18] разработали недорогую автоматизированную систему титрования с использованием колориметрического определения конечной точки, а Косенков и Косенков [19] продемонстрировали автоматическое титрование с использованием методов компьютерного зрения. Более поздние работы расширили эту область за счет обзора колориметрического обнаружения с помощью ИИ [20] и роботизированных колориметрических платформ титрования с мониторингом в реальном времени на основе компьютерного зрения [21].
Однако эти предыдущие подходы существенно отличаются от настоящей работы. Многие из них основаны на отборе проб реагирующего раствора и его переносе в отдельную кювету или индикаторную полоску для автономного анализа, или же они сосредоточены исключительно на бинарном определении конечной точки, а не на приблизительной непрерывной оценке pH. Кроме того, большинство из них предназначены для использования в аналитических лабораториях и не учитывают образовательную реализацию.
В отличие от других исследований, данное исследование напрямую визуализирует реагирующую жидкость внутри титрационного сосуда в режиме реального времени, извлекает RGB-признаки без необходимости отдельной выборки и применяет как регрессионные, так и классификационные модели для оценки pH во всем диапазоне перехода BTB. Весь рабочий процесс — от сборки оборудования до обучения и оценки модели — организован как единое, недорогое лабораторное занятие для естественнонаучного образования, позволяющее студентам интегрировать химию, программирование и анализ данных в одном занятии.
2. Теоретические основы
2.1. Колориметрический анализ индикаторов pH
Прямое измерение pH в различных материалах долгое время представляло собой сложную задачу для ученых. Крейг [22] предложил метод измерения кислотности аэрозоля с использованием индикаторных бумаг pH в сочетании с колориметрическим анализом на основе RGB, включая такие модели, как R/G против pH и GB против pH. Основываясь на этом подходе, Ли [23] предложил линейную модель, связывающую значения RGB с прогнозируемым pH (pH predict ). Поскольку цвет представлен комбинацией значений R (красный), G (зеленый) и B (синий), линейная комбинация этих трех основных цветов может отражать цветовые характеристики и, в свою очередь, pH, связанный с этим цветом. Для учета изменений интенсивности света каждый цветовой канал нормализуется с использованием следующих уравнений:
Линейная модель затем выражается как pH predict = aR normal + bG normal + cB normal, где a, b и c — коэффициенты. В качестве эталона для измерения pH с помощью индикаторных бумаг обычно используется цветовая шкала. Выполняя линейную регрессию на цветовой шкале, можно оценить вектор коэффициентов [a, b, c], который затем можно использовать для прогнозирования pH (pH predict) неизвестных образцов.
Ханал [7] оценил комбинации моделей машинного обучения и цветовых пространств изображений, включая RGB, HSV и LAB, для прогнозирования концентраций аналита. Модели, которые использовали как цвет образца, так и эталонный цвет, показали улучшенную точность прогнозирования. Элсенети [24] применил методы машинного обучения к обычной индикаторной бумаге для точного определения pH, при этом модель регрессора K-соседей достигла значения R² равного 0,995. Хоу [25] сообщил о простом и надежном методе визуализации и измерения pH отдельных клеток путем сочетания УФ-видимой спектроскопии с обычными индикаторами pH.
Выбор цветового пространства RGB вместо альтернативных представлений (CIELab, HSV и XYZ) был основан на ряде технических и практических соображений. Цветовое пространство RGB обеспечивает прямое соответствие выходным данным цифровых камер, исключая дополнительные этапы преобразования цветового пространства, которые могут привести к вычислительным ошибкам и задержкам обработки.
2.2. Компьютерное зрение
Технология компьютерного зрения (CV) позволяет машинам интерпретировать и понимать визуальный мир, преобразуя изображения в числовую или символическую информацию. Она включает в себя множество этапов, таких как получение изображения, предварительная обработка, сегментация, извлечение признаков и анализ [26]. Системы CV используют цифровые камеры, датчики и программное обеспечение для обработки изображений, чтобы получать изображения из реальной среды. Для улучшения качества изображения и обеспечения согласованного анализа применяются методы предварительной обработки изображений, такие как нормализация, повышение контраста и шумоподавление. Интеграция ИИ и CV привела к значительным достижениям в таких областях, как обнаружение объектов, распознавание лиц и автономные транспортные средства.
В контексте колориметрического анализа для улучшения интерпретации колориметрических данных на основе индикаторов использовались технологии искусственного интеллекта и компьютерного зрения [24, 25]. Обучая модели машинного обучения на больших наборах данных изображений, исследователи могут моделировать взаимосвязь между значениями RGB и химическими свойствами, такими как pH [7]. Эти достижения также способствовали автоматическому определению конечной точки в экспериментах по титрованию [18]. В настоящем исследовании изменение цвета бромтимолового синего (БТБ) во время титрования анализируется с помощью системы компьютерного зрения в сочетании с машинным обучением. Такая конфигурация позволяет более объективно, точно и воспроизводимо определять конечную точку, тем самым повышая качество и надежность экспериментальных результатов [19].
2.3. Цифровые технологии в естественнонаучном образовании
Применение цифровых технологий в образовании получило значительный импульс благодаря развитию доступных вычислительных платформ, программного обеспечения с открытым исходным кодом и фреймворков машинного обучения [1, 2, 3]. В естественнонаучном образовании технологически усовершенствованные учебные среды предоставляют студентам возможности для участия в подлинных научных исследованиях, развития навыков работы с данными и знакомства с междисциплинарным характером современных исследований. Интеграция вычислительных инструментов в лабораторные условия преобразует пассивное наблюдение в активный, основанный на данных эксперимент, что соответствует современным образовательным концепциям, которые делают акцент на компетенциях в области STEM и навыках XXI века.
Одноплатные компьютеры, такие как Raspberry Pi, стали практичными образовательными платформами, позволяющими с минимальными затратами обучаться программированию, электронике и анализу данных на практике. В сочетании с библиотеками компьютерного зрения (например, OpenCV) и фреймворками машинного обучения (например, scikit-learn) эти платформы предлагают удобную среду для разработки экспериментов с использованием современных технологий, которые сохраняют как образовательную ценность, так и научную строгость. Такие системы отвечают растущей потребности в методах обучения, включающих цифровые инструменты, как отмечается в современной литературе по образовательным технологиям.
3. Материалы и методы
3.1. Настройка оборудования
Экспериментальное устройство состоит из Raspberry Pi, веб-камеры, монитора, блока питания и клавиатуры; принципиальная схема показана на рисунке 1. Данная конфигурация оборудования была выбрана из-за ее пригодности для использования в образовательных учреждениях, где важны экономичность и простота сборки. Raspberry Pi служил центральным процессором для захвата изображений в реальном времени и обработки данных. Веб-камера использовалась в качестве устройства ввода изображений для сбора RGB-данных, а USB-клавиатура — для ввода команд и управления системой. Для обеспечения стабильной работы Raspberry Pi использовался специальный адаптер питания.
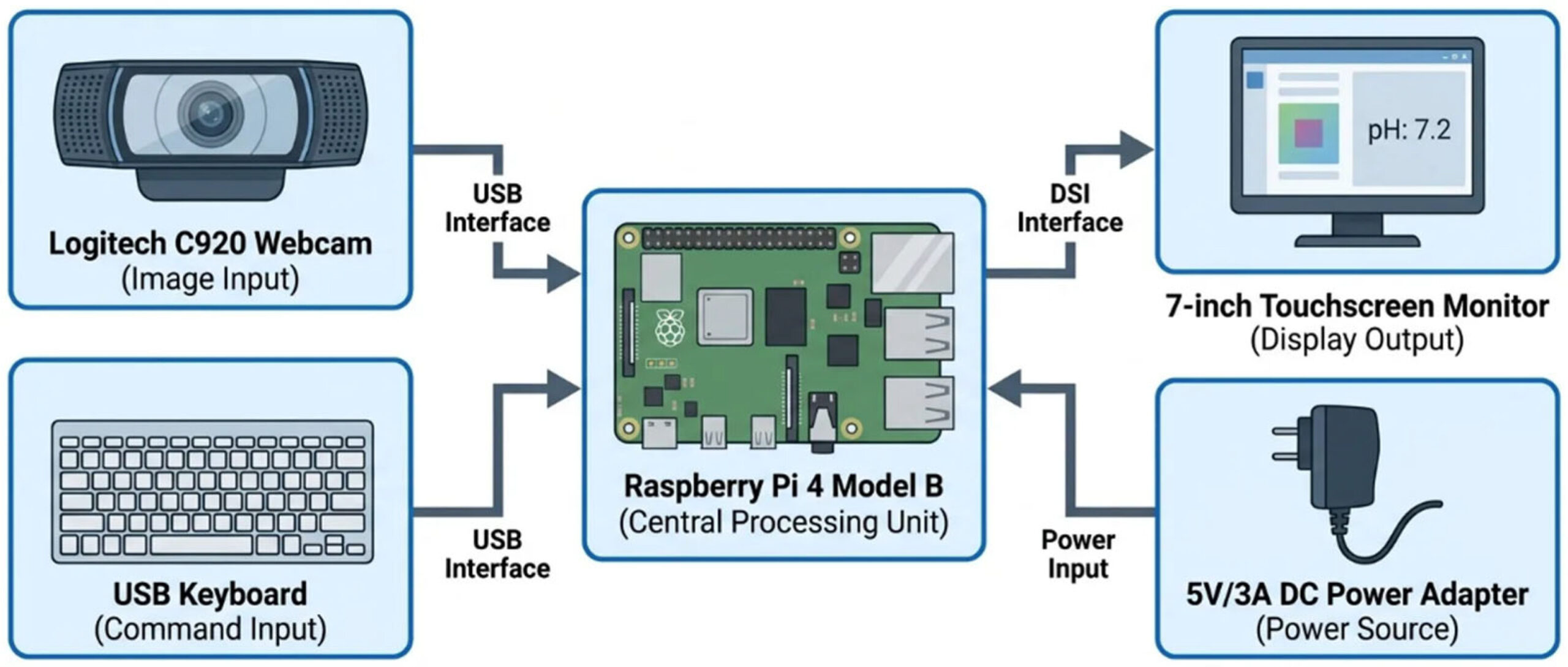
Рисунок 1. Схема подключения Raspberry Pi с веб-камерой.
3.2. Титрование раствора БТБ
Экспериментальная установка показана на рисунке 2. Были приготовлены образцы растворов со значениями pH в диапазоне приблизительно от 4,50 до 11,00, и в каждый раствор был добавлен индикатор BTB. Цветные изображения были получены с помощью веб-камеры и преобразованы в данные RGB, которые затем использовались для обучения моделей машинного обучения. Точные значения pH измерялись одновременно с помощью калиброванного цифрового pH-метра.
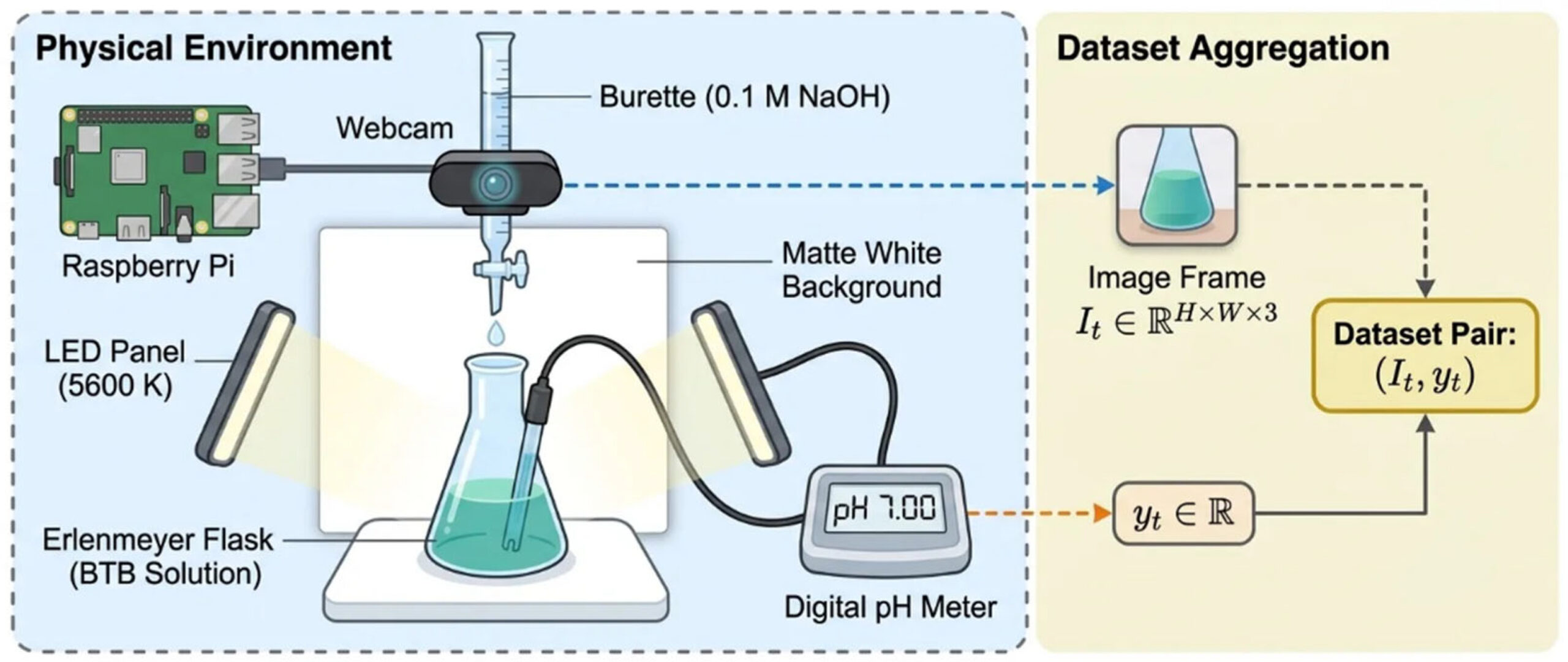
Рисунок 2. Экспериментальная установка для титрования с использованием Raspberry Pi, подключенного к веб-камере.
3.2.1. Приготовление стандартных буферных растворов
Стандартные буферные растворы с pH 4,00, 7,00 и 9,18 реактивной чистоты были приготовлены при 25 °C. Для буферного раствора с pH 4,00 точно взвесили 10,21 г гидрофталата калия (KHC₈H₄O₄ ) , растворили в 800 мл сверхчистой воды, перенесли в мерную колбу объемом 1 л и разбавили до метки сверхчистой водой. Для буферного раствора с pH 7,00 точно взвесили 3,39 г дигидрофосфата калия (KH₂PO₄ ) и 3,55 г гидрофосфата натрия (Na₂HPO₄ ) и приготовили их аналогичным образом. Для буферного раствора с pH 9,18 точно взвесили 3,81 г декагидрата тетрабората натрия ( Na₂B₄O₇ · 10H₂O ) и приготовили их аналогичным образом . Все буферные растворы готовились в день использования и хранились в герметичной упаковке до калибровки, чтобы минимизировать поглощение CO₂ и дрейф pH.
3.2.2. Этапы калибровки
Перед калибровкой pH-электрод промывали сверхчистой водой и аккуратно просушивали промокательной бумагой. Электрод погружали в буферный раствор с pH 7,00 до стабилизации показаний. Этот процесс повторяли с буферными растворами с pH 4,00 и 9,18. Цикл калибровки повторяли до тех пор, пока показания во всех буферных растворах не стабилизировались в пределах ±0,02 единиц pH от известных значений.
3.2.3. Извлечение данных о цвете из экспериментов по титрованию
Порошок БТБ полностью растворили в этаноле (20 мл), затем добавили дистиллированную воду (80 мл), доведя общий объем раствора до 100 мл. Приблизительно 60 мкл раствора БТБ добавили к 3–5 мл буферного раствора с pH 7,0. 50 мл раствора БТБ с pH 7,0 поместили в колбу Эрленмейера и титровали 0,1 М раствором NaOH, контролируя изменение цвета.
Цветные изображения растворов в процессе кислотно-щелочного титрования были получены с помощью веб-камеры, а данные изображений были преобразованы в формат RGB. Был обеспечен строгий контроль условий окружающего освещения. Освещение обеспечивалось двумя светодиодными панелями с коррелированной цветовой температурой 5600 К. Настройки камеры были стандартизированы путем отключения автоматического баланса белого. Образцы размещались на матовой белой подложке для уменьшения вторичных оптических артефактов.
3.3. Анализ данных и прогнозирование
Исследование проходило через следующие основные этапы: сбор данных, предварительная обработка, кластерный анализ, регрессионный анализ и оценка модели классификации. Эти этапы использовались для анализа и прогнозирования изменений цвета раствора путем объединения компьютерного зрения с машинным обучением, как показано на рисунке 3 [26].
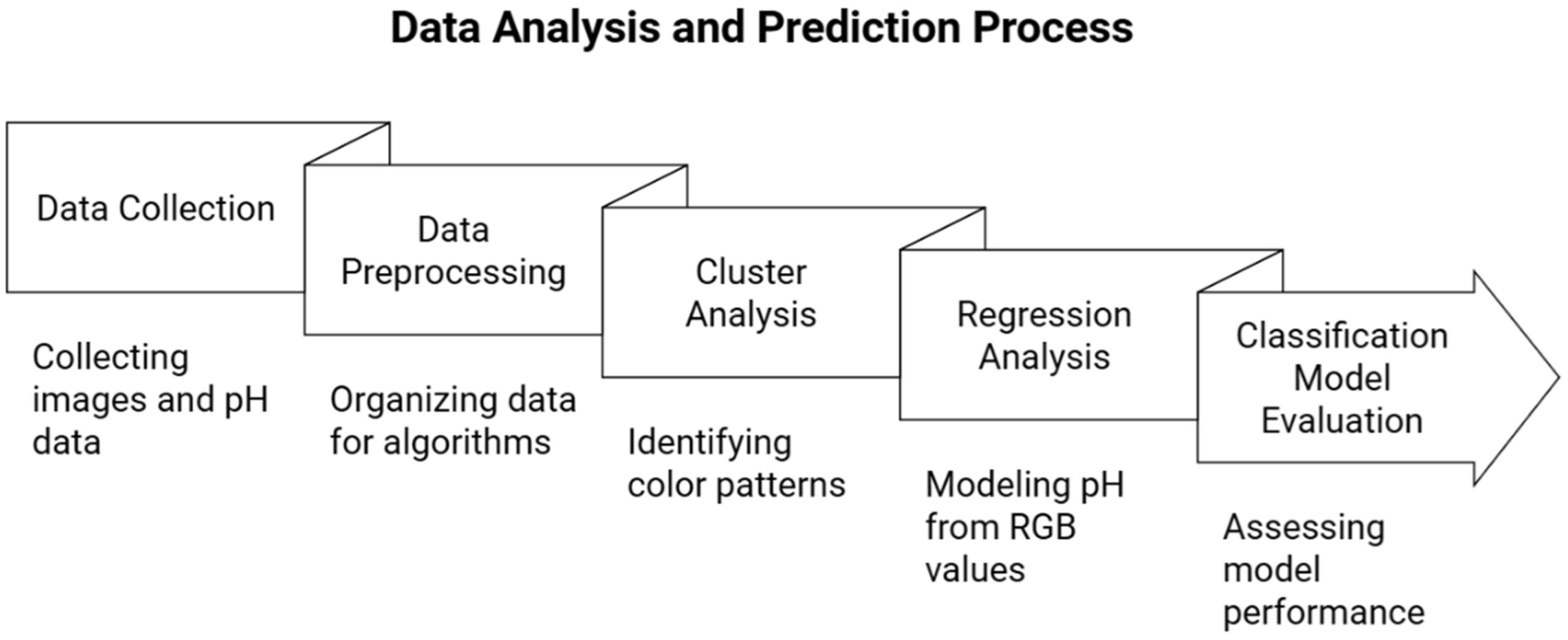
Рисунок 3. Процесс анализа данных и прогнозирования.
На этапе сбора данных в различные кислые, щелочные или нейтральные растворы добавляли индикатор бромтимоловый синий (БТБ) для изменения цвета в зависимости от значений pH. Для получения изображений растворов использовалась веб-камера высокого разрешения, при этом одновременно измерялось точное значение pH каждого образца с помощью pH-метра.
Этап предварительной обработки организовал собранные данные изображений для использования в анализе машинного обучения [27]. Исходные кадры (4032 × 3024 пикселей; 54 изображения) сначала были обрезаны по центру до квадратного формата (3024 × 3024 пикселей) для стандартизации поля зрения и удаления краевых артефактов. Затем каждый обрезанный кадр был разделен на фрагменты размером 336 × 336 пикселей, в результате чего был получен расширенный набор данных на уровне фрагментов, состоящий из 4374 изображений [28]. Изображения обрабатывались в OpenCV путем определения и обрезки областей, преобразования цвета (BGR в RGB), шумоподавления, нормализации освещения, извлечения фрагментов и вычисления среднего значения для каждого фрагмента. Векторы признаков состояли из усредненных по фрагментам значений R, G и B вместе с нормализованными значениями каналов. Псевдокод приведен в Приложении A.
Для обеспечения независимости между обучающим и тестовым наборами данных разделение данных проводилось на уровне исходных изображений перед извлечением фрагментов. 54 исходных изображения были сначала случайным образом разделены на обучающий (43 изображения, 80%) и тестовый (11 изображений, 20%) наборы. Затем фрагменты извлекались независимо из каждого набора, в результате чего было получено 3499 обучающих фрагментов и 875 тестовых фрагментов. Эта стратегия разделения на уровне изображений предотвращает утечку данных, которая могла бы возникнуть, если бы фрагменты одного и того же исходного изображения присутствовали как в обучающем, так и в тестовом наборах, что обеспечивает более строгую оценку обобщающей способности модели. Эксперименты по титрованию проводились в течение 6 независимых экспериментальных сессий на протяжении 4 недель, при этом в каждой сессии было получено 8–10 изображений при разных уровнях pH для обеспечения воспроизводимости эксперимента.
Полный алгоритм получения изображений и извлечения ROI показан на рисунке 4. Для классификации изображений на три отдельных кластера в пространстве признаков RGB применялась кластеризация методом k-средних [29]. Затем для количественной оценки взаимосвязи между значениями RGB и pH использовался множественный линейный регрессионный анализ [30, 31]. Было реализовано и оценено несколько моделей классификации машинного обучения, включая метод k-ближайших соседей (KNN), случайный лес, градиентный бустинг, AdaBoost и метод опорных векторов (SVM) [32, 33, 34, 35, 36, 37]. Производительность модели оценивалась с помощью перекрестной проверки, а также метрик точности, прецизии, полноты и F1-меры [38, 39].
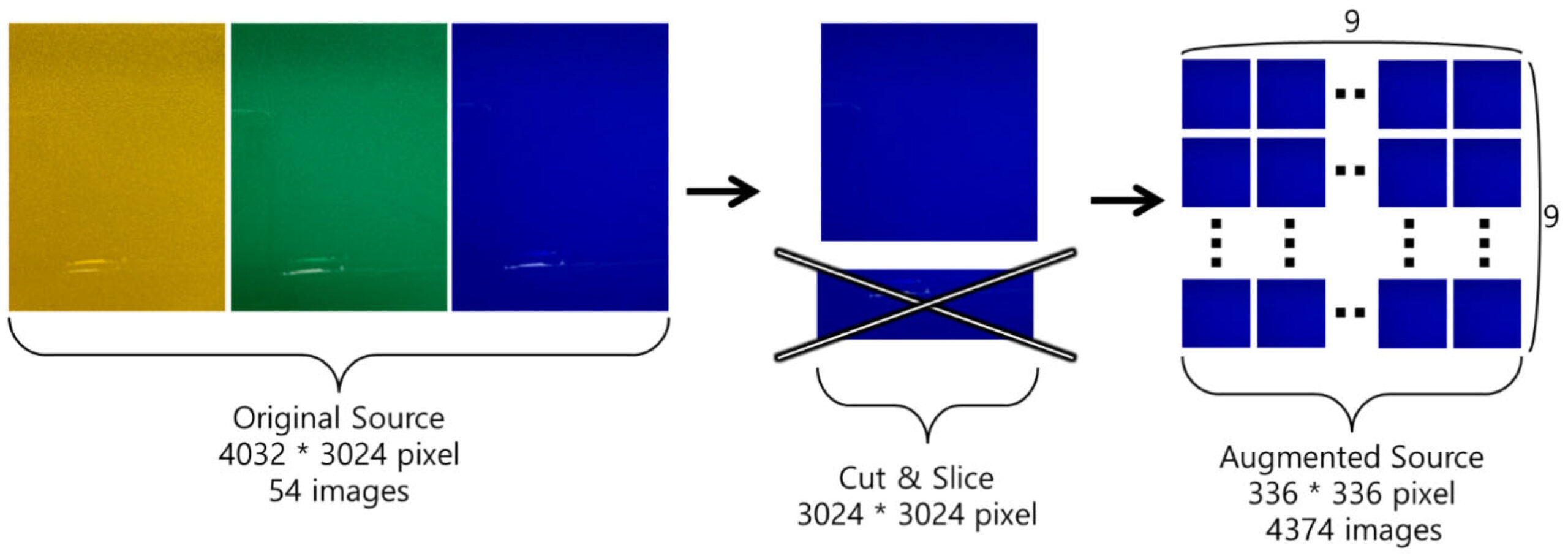
Рисунок 4. Стратегии формирования воронки продаж и рентабельности инвестиций.
4. Результаты
4.1. Результаты кластерного анализа
Результаты кластеризации, представленные на рисунке 5, показывают, что набор данных можно разделить на отдельные группы в соответствии с характеристиками переменных RGB. Каждый кластер демонстрирует специфический цветовой профиль, указывающий на четкую связь с распределением pH. Для определения оптимального числа кластеров был использован метод «локтя», и кривая показывает четкий изгиб при k = 3.
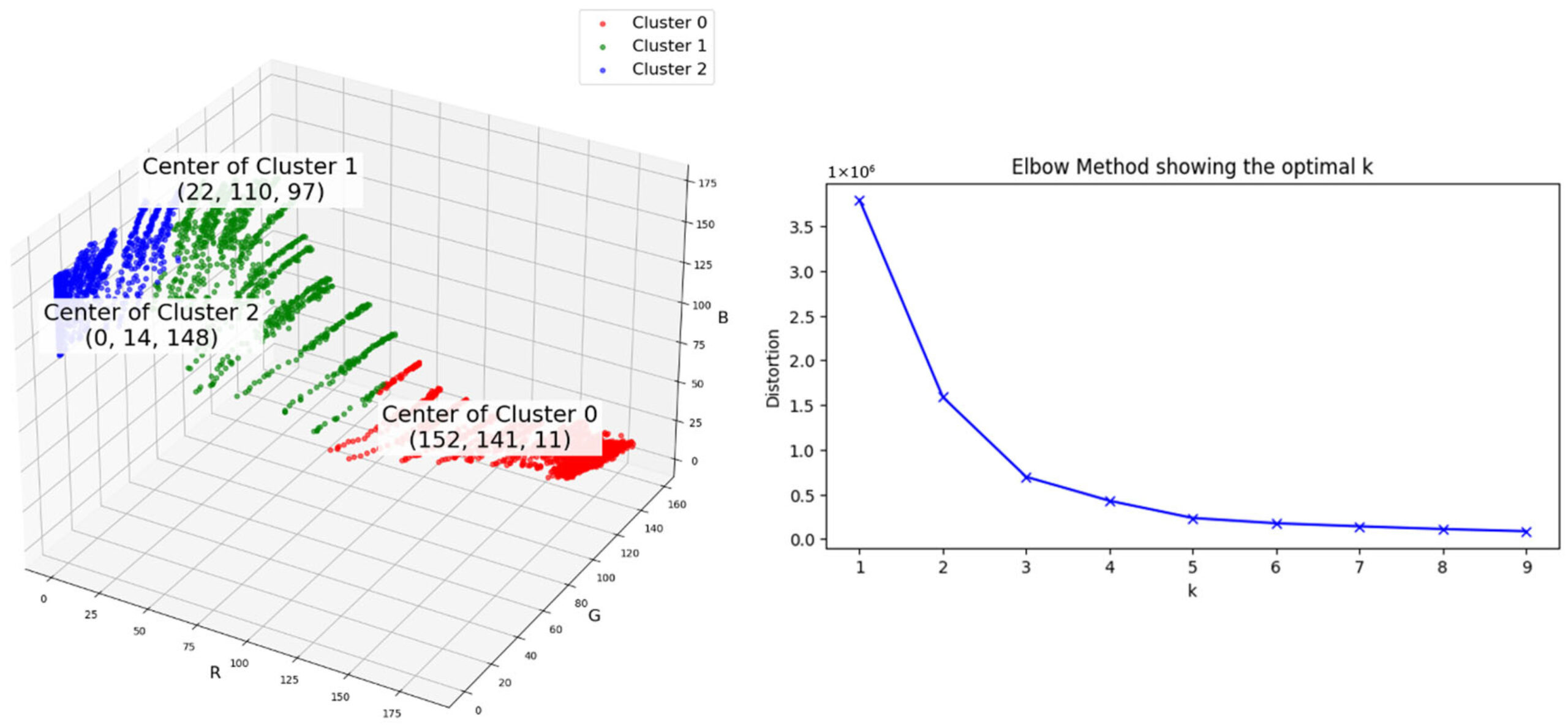
Рисунок 5. Метод «локтя» и результаты кластеризации, показывающие три оптимальных кластера.
Подробные результаты кластеризации суммированы в таблице 1. Границы кластеров, определенные алгоритмом K-средних (pH 6,72 и pH 7,71), точно соответствуют теоретической переходной зоне индикатора BTB (pH 6,0–7,6). Это соответствие имеет химическое значение: ниже pH 6,72 BTB преимущественно существует в протонированной (желтой) форме с высокими значениями R и низкими значениями B; между pH 6,72 и 7,71 индикатор претерпевает характерный переход от желтого к синему цвету, образуя промежуточные зеленые оттенки; а выше pH 7,71 доминирует депротонированная (синяя) форма с высокими значениями B и незначительными значениями R, как показано на рисунке 6. Соответствие между границами кластеров, определенными на основе данных, и известным диапазоном перехода BTB подтверждает химическую основу подхода к классификации на основе RGB.
Таблица 1. Сводка результатов кластеризации.
| Номер кластера. | Диапазон pH | Среднее значение R | Среднее значение G | Среднее значение B |
|---|---|---|---|---|
| 0 | 4,50–6,72 | 153.0 | 141.1 | 11.6 |
| 1 | 6.72–7.71 | 22.4 | 110.1 | 97,8 |
| 2 | 7.71–11.00 | 0,5 | 14.4 | 148.6 |
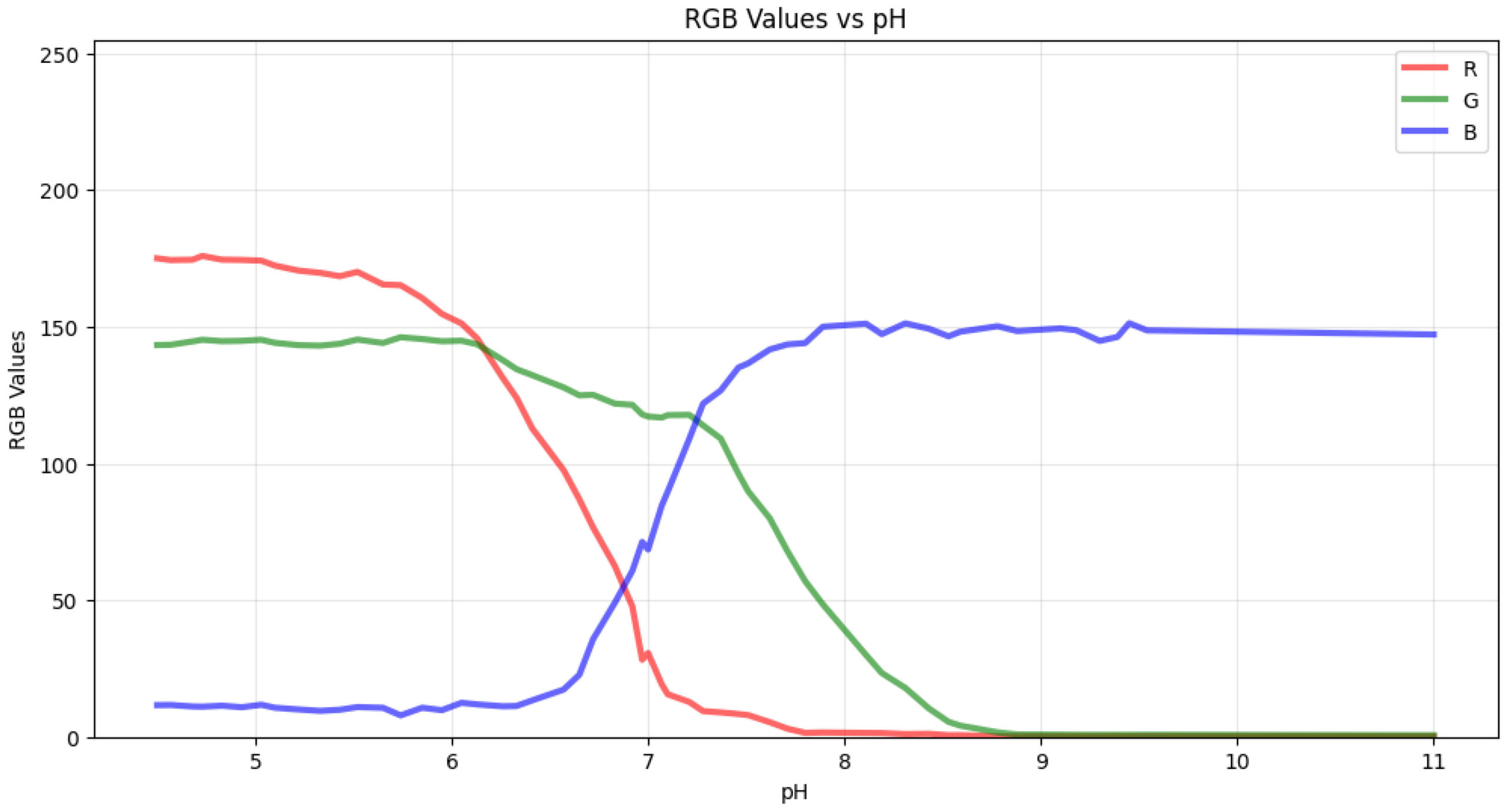
Рисунок 6. Значения RGB в зависимости от изменений pH.
4.2. Результаты множественного регрессионного анализа
В результате множественного регрессионного анализа были сопоставлены четыре модели: линейная регрессия, регрессия на основе дерева решений, регрессия на основе случайного леса и регрессия на основе опорных векторов, как показано в таблице 2. Среди них модель случайного леса показала наилучшие результаты, с коэффициентом детерминации R² более 0,85 на тестовом наборе данных и наименьшими значениями MSE и MAE, как показано в таблице 3.
Таблица 2. Результаты множественного регрессионного анализа.
| Модель | Поезд МСЕ | 5-кратная MSE | Тест MSE | Тестовая среднеквадратичная ошибка (RMSE) | Тест MAE | Р 2 |
|---|---|---|---|---|---|---|
| Линейная регрессия | 0,0450 | 0,0480 | 0,0520 | 0.2280 | 0.1800 | 0,75 |
| Дерево решений | 0.0300 | 0,0500 | 0,0650 | 0.2550 | 0.2000 | 0,70 |
| Случайный лес | 0.0200 | 0,0350 | 0.0400 | 0.2000 | 0.1500 | 0,85 |
| Опорный вектор | 0,0550 | 0.0600 | 0.0700 | 0.2650 | 0.2100 | 0,68 |
Таблица 3. Результаты настройки гиперпараметров.
| Модель | Оптимальные параметры | Тест MSE | Тестовая среднеквадратичная ошибка (RMSE) | Р 2 |
|---|---|---|---|---|
| Случайный лес | Деревьев = 150, Максимальная глубина = 10 | 0,0380 | 0.1950 | 0,87 |
| Опорный вектор | Ядро = RBF, C = 1,5 | 0,0650 | 0.2550 | 0,70 |
Умеренные значения R² , наблюдаемые во всех моделях регрессии, отражают присущую сложность прогнозирования точных значений pH на основе данных RGB в узком диапазоне переходов BTB (pH 6,0 – 7,6). В этом интервале тонкие цветовые градации соответствуют небольшим различиям в pH, что делает точную регрессию более сложной, чем категориальная классификация. Тем не менее, модель случайного леса достигла средней абсолютной ошибки (MAE) ниже 0,3 единиц pH, как показано на рисунке 7, что достаточно для образовательных приложений титрования, которые являются основной целью данного исследования.
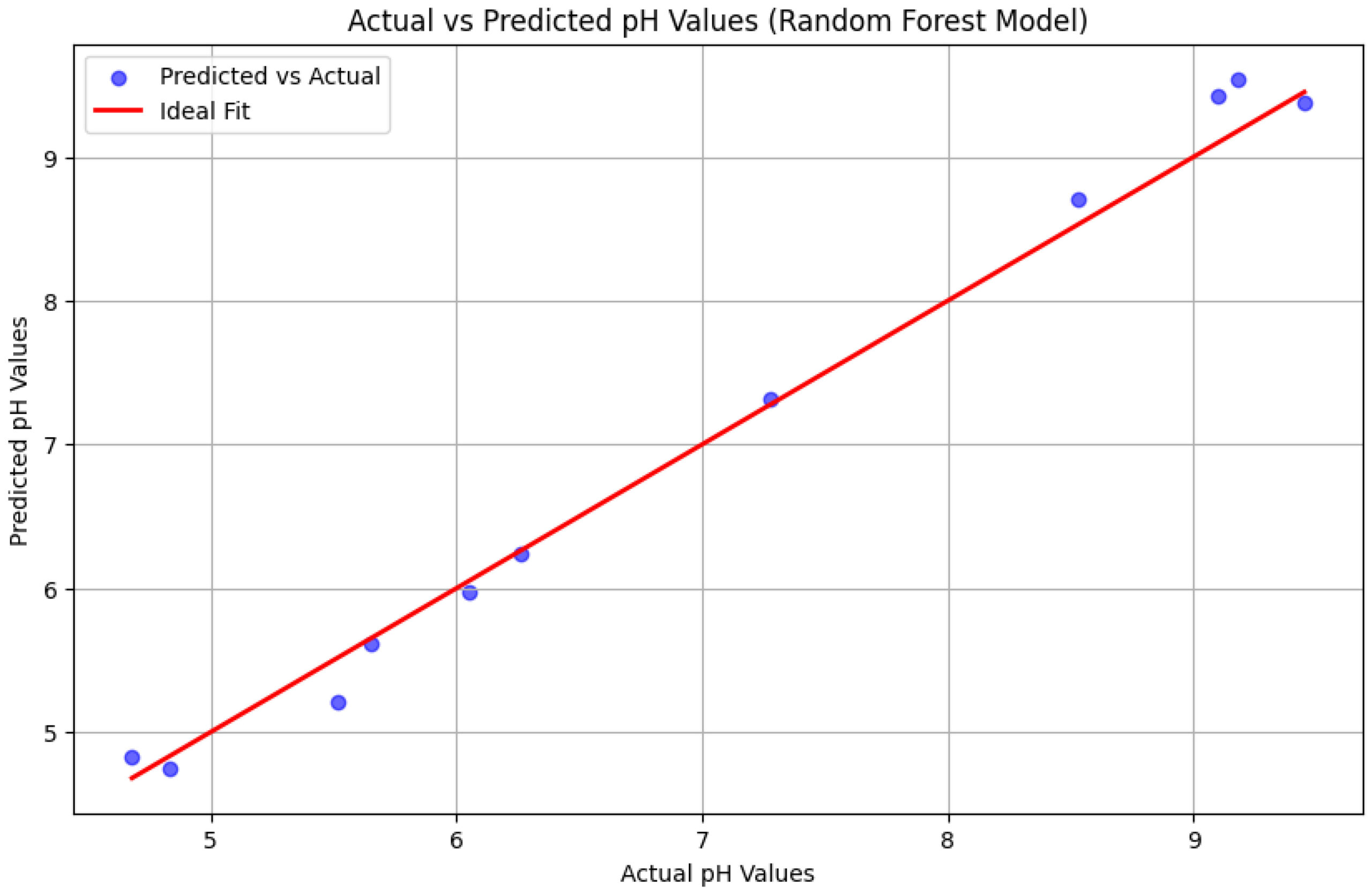
Рисунок 7. Пошаговое сравнение фактических и прогнозируемых значений pH в модели случайного леса.
4.3. Результаты модели классификации
В ходе классификационного анализа были определены три класса с использованием пороговых значений, полученных на основе результатов кластеризации методом K-средних: кислые (pH 4,50–6,13), нейтральные (pH 6,26–7,62) и основные (pH 7,71–11,00). Эта трехклассовая схема была мотивирована как данными, так и образовательной значимостью. С точки зрения данных, анализ кластеризации методом K-средних в разделе 4.1 выявил три естественно разделимых кластера RGB, при этом график инерции внутри кластеров показал четкую точку перегиба при k = 3, подтверждая, что три кластера наилучшим образом отражают структуру в пространстве признаков RGB. С образовательной точки зрения, три класса напрямую соответствуют категориям кислотность–нейтральность–основность, которые изучаются студентами в стандартных естественнонаучных учебных программах, что делает результаты классификации сразу же интерпретируемыми в контексте обучения.
Эти три категории также соответствуют хорошо известным зонам цветового перехода индикатора BTB (желтый, зеленый и синий). Следует отметить, что данное исследование также предоставляет непрерывную оценку pH с помощью регрессионных моделей (раздел 4.2); таким образом, трехклассовая классификация дополняет, а не заменяет регрессионный анализ, предлагая быструю категориальную оценку состояния раствора. Как метод k-ближайших соседей (KNN), так и метод случайного леса показали высокую точность ( таблица 4 ). Однако эта высокая точность в значительной степени обусловлена хорошо разделенными цветовыми переходами BTB, которые создают четко различимые кластеры RGB; задача была бы более сложной для индикаторов с менее четкими или перекрывающимися изменениями цвета. Метод случайного леса также показал стабильную прогностическую эффективность, когда границы классов были менее четко определены, как показано в таблице 5 .
Таблица 4. Результаты модели классификации.
| Модель | Точность | Точность | Отзывать | Оценка F1 |
|---|---|---|---|---|
| КНН | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Случайный лес | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Градиентный бустинг | 0.9977 | 0.9977 | 0.9977 | 0.9977 |
| AdaBoost | 0.7909 | 0.8689 | 0.7909 | 0.7707 |
| SVM | 0.9977 | 0.9977 | 0.9977 | 0.9977 |
Таблица 5. Матрица ошибок для модели случайного леса.
| Прогнозируемое значение: 0 | Прогнозируемый 1 | Прогнозируется 2 | |
|---|---|---|---|
| Фактический класс 0 | 308 | 0 | 0 |
| Фактический класс 1 | 0 | 284 | 0 |
| Фактический класс 2 | 0 | 0 | 283 |
Анализ важности признаков в модели случайного леса показал, что канал R был наиболее влиятельным предиктором (приблизительно 40,7%), за ним следовали канал G (35,6%) и канал B (23,7%).
Идеальная точность классификации (100%), представленная в таблице 4, отражает результаты на отложенном тестовом наборе и требует тщательной интерпретации. Этот результат, вероятно, объясняется хорошо разделенными цветовыми кластерами BTB, наблюдаемыми в разных диапазонах pH, как показано на рисунке 5. BTB создает хорошо различимые цвета: желтый для кислых, зеленый для нейтральных и синий для щелочных растворов, которые образуют четко разделенные группы в пространстве признаков RGB.
Для дальнейшей оценки возможности переобучения была дополнительно выполнена 5-кратная перекрестная проверка на обучающем наборе, что дало стабильные средние значения точности 99,5 ± 0,4% для случайного леса и 99,3 ± 0,6% для KNN по всем фолдам. Кроме того, разделение изображений на обучающую и тестовую выборки, описанное в разделе 3.3, гарантировало, что обучающие и тестовые фрагменты происходят из разных изображений, тем самым снижая риск утечки данных. Тем не менее, относительно небольшое количество исходных изображений и стратегия аугментации на основе фрагментов могут все еще завышать показатели производительности.
5. Обсуждение
Предыдущие исследования в основном анализировали цвет индикатора с помощью полосок pH [40, 41], в то время как связанные с этим недавние работы были сосредоточены на определении конечной точки, колориметрическом анализе с помощью ИИ или автоматизации титрования [18, 20, 21]. В отличие от этого, в настоящем исследовании pH оценивается непосредственно по изображениям реакционного раствора в реальном времени, а сборка оборудования, обработка изображений и машинное обучение интегрированы в единую учебную лабораторную деятельность. Это отличает наш подход от большинства существующих систем, которые, как правило, предназначены для использования в аналитических лабораториях, а не для образовательных целей.
Изменение цвета BTB хорошо подходит для индикации конечной точки и для приблизительной оценки pH в пределах его переходного интервала, однако полученные оценки на основе RGB предназначены для образовательных целей данного исследования и не должны интерпретироваться как замена прямому высокоточному измерению pH.
Бромотимоловый синий (БТБ) был выбран потому, что его цветовые переходы в диапазоне pH 6,0–7,6 приводят к измеримым сдвигам RGB в спектре от кислотных до щелочных сред. Среди протестированных моделей регрессии наилучшие прогностические показатели показал случайный лес. В задаче классификации как KNN, так и случайный лес достигли 100% точности на данном наборе данных, что объясняется хорошо разделенными кластерами желтого/зеленого/синего цветов БТБ; для индикаторов с более плавными или непрерывными цветовыми сдвигами достижение сопоставимой точности, вероятно, потребует более сложных представлений признаков или архитектур моделей.
Ранжирование важности признаков в случайном лесу показало, что канал R внес наибольший вклад (40,7%), за ним следуют канал G (35,6%) и канал B (23,7%), что соответствует цветовому переходу БТБ. Поскольку для разделения обучающего и тестового наборов данных применялось разделение на уровне изображений, прямая утечка данных сводится к минимуму; Однако фрагменты, полученные в ходе одной и той же сессии титрования, могут иметь общие характеристики фона и освещения, и это следует учитывать при интерпретации сообщаемой точности.
5.1. Образовательные последствия и применение
Данное исследование актуально для темы специального выпуска, поскольку демонстрирует один из подходов к интеграции цифровых технологий в естественнонаучное образование. Система использует недорогое оборудование и программное обеспечение с открытым исходным кодом для преобразования обычного эксперимента по титрованию в лабораторную работу, в которой студенты одновременно занимаются химией, программированием и анализом данных.
С точки зрения стоимости, подход к оценке pH на основе RGB требует только веб-камеры и Raspberry Pi, а общие затраты на оборудование составляют приблизительно 100–150 долларов США. Такой уровень стоимости приемлем даже для школ с ограниченным лабораторным бюджетом. В ходе эксперимента студенты собирают оборудование, пишут скрипты на Python (3.12) для захвата и предварительной обработки изображений, а также обучают модели машинного обучения — и все это за одно лабораторное занятие.
Автоматическое определение конечной точки также снижает субъективность, связанную с визуальной оценкой цвета, которая является распространенным источником ошибок при проведении титрования студентами. Поскольку система записывает каждый кадр вместе с его значениями RGB, преподаватели могут просматривать данные со студентами и обсуждать различия между человеческим наблюдением и решениями алгоритма.
Данная методика также поддерживает открытые исследовательские задачи. Например, студенты могут изучить, как условия освещения влияют на значения RGB, заменить BTB другим индикатором и сравнить производительность модели или изменить размер сетки, используемой при усреднении, и наблюдать за влиянием на ошибку прогнозирования. Эти действия выходят за рамки фиксированного протокола и поддерживают цикл гипотезы, эксперимента и оценки.
Расширение обучающей выборки за счет включения других распространенных индикаторов, таких как фенолфталеин и метиловый оранжевый, расширит диапазон титрований, поддерживаемых системой. Подключение Raspberry Pi к общему серверу или облачному ноутбуку также позволит нескольким группам студентов объединять свои данные, тем самым увеличивая размер набора данных и поддерживая совместную работу с данными.
5.2. Ограничения
Следует отметить несколько ограничений данного исследования. Во-первых, набор данных был создан из 54 исходных изображений титрования, которые были разделены на фрагменты для создания расширенного набора данных из 4374 образцов. Хотя разделение данных на уровне изображений снижает прямую утечку данных, фрагменты, полученные из одного цикла титрования, могут иметь общие характеристики освещения и фона, что потенциально может завышать производительность модели по сравнению с полностью независимыми образцами. Поэтому в будущих исследованиях следует использовать независимо собранные наборы данных для валидации, чтобы усилить оценку обобщающей способности модели.
Во-вторых, экспериментальная проверка ограничена одним индикатором (БТБ) с относительно узким рабочим диапазоном pH (pH 6,0–7,6). Другие индикаторы, такие как фенолфталеин (pH 8,2–10,0) или метиловый оранжевый (pH 3,1–4,4), демонстрируют различные цветовые переходы и диапазоны pH, и применимость данного подхода к этим индикаторам не была проверена. Связанная с этим проблема заключается в том, что высокая точность классификации, о которой сообщается здесь, тесно связана с четким разделением цветов БТБ, что упрощает задачу классификации. Для индикаторов с менее выраженными, постепенными или перекрывающимися изменениями цвета в зависимости от уровня pH такой же уровень точности может быть недостижим, и может потребоваться дополнительная разработка признаков или более сложные модели. Поэтому разработанную структуру следует рассматривать скорее как подтверждение концепции, чем как общий аналитический метод, и ее расширение на другие индикаторы является необходимым следующим шагом для будущих исследований.
Во-третьих, колориметрический анализ на основе RGB по своей природе чувствителен к условиям освещения. Хотя в данном исследовании использовалось контролируемое освещение (раздел 3.2.3), изменения окружающего освещения, характеристики сенсора камеры и настройки баланса белого могут снизить воспроизводимость измерений RGB в различных экспериментальных условиях. Производительность системы в различных условиях окружающей среды еще не была систематически оценена, и в будущих исследованиях следует протестировать систему в различных условиях освещения, с использованием различных устройств визуализации и типов индикаторов для установления более широкой области применения.
В целом, данное исследование демонстрирует, как недорогое оборудование и стандартные модели машинного обучения могут использоваться в контексте учебной лаборатории. Его основной вклад заключается скорее в практической образовательной структуре, чем в методологических достижениях в аналитической химии или машинном обучении.
В будущих исследованиях следует изучить показатели с более широким диапазоном pH, чтобы выйти за пределы относительно узкого рабочего диапазона BTB, а также разработать адаптивные стратегии нормализации для использования в различных условиях окружающей среды.
Хотя данное исследование ограничено BTB и относительно небольшим набором из 54 оригинальных изображений, предложенная структура может быть расширена на другие показатели и более крупные наборы данных. Стратегия аугментации на основе фрагментов оказалась эффективной для увеличения размера выборки, но она также может вносить корреляции между обучающими выборками; этот вопрос следует решить в будущих исследованиях с помощью дополнительных независимо собранных экспериментальных данных.
6. Выводы
В данном исследовании для приблизительной оценки pH и определения конечной точки в титровании на основе BTB были объединены компьютерное зрение и машинное обучение. Raspberry Pi в режиме реального времени захватывал изображения раствора, а усреднение RGB-фрагментов по сетке уменьшало шум, вызванный пульсациями и локальными изменениями цвета. Среди протестированных моделей регрессии наилучшие результаты показал Random Forest (R² > 0,85, MAE < 0,3 единиц pH). Для классификации по трем классам (кислые, нейтральные и основные) как Random Forest, так и KNN достигли идеальной точности на тестовом наборе, хотя эти результаты следует интерпретировать в рамках концепции и с учетом ограничений данных, обсуждавшихся выше.
Поскольку весь конвейер обработки данных, от настройки оборудования до оценки модели, работает на недорогих компонентах с открытым исходным кодом, его можно использовать в самых разных условиях в школах и университетах. Одно лабораторное занятие позволяет студентам работать с аналитической химией, обработкой изображений и машинным обучением в рамках одной экспериментальной схемы. Поскольку участки в рамках одного титрования могут иметь общие фоновые и световые характеристики, будущие оценки должны включать независимо собранные наборы данных. Для подтверждения обобщаемости подхода необходимо протестировать систему при различном освещении, с использованием различных устройств визуализации и с индикаторами, отличными от BTB.
Приложение А. Псевдокод
| Алгоритм А1. Сбор и предварительная обработка данных. |
| PROCEDURE ACQUISITION_AND_PREPROCESSING(camera, Wref, M_optional) |
| DISABLE_AUTO_WHITE_BALANCE(camera) |
| SET_FIXED_EXPOSURE(camera) |
| I ← CAPTURE_FRAME(camera) |
| IF M_optional IS NOT NULL THEN |
| I ← APPLY_MASK(I, M_optional) |
| ENDIF |
| I ← CVT_COLOR(I, BGR_TO_RGB) |
| I ← DENOISE(I, method = {GAUSSIAN or MEDIAN}) |
| (μR, μG, μB) ← MEAN_RGB(Wref) |
| I’ ← CLIP([ I.R/μR, I.G/μG, I.B/μB ], 0, 255) |
| RETURN I’ |
| ENDPROCEDURE |
| Алгоритм A2. Усреднение на основе сетки |
| PROCEDURE GRID_BASED_AVERAGING(I’, G=10, z_thresh=2.5) |
| CELLS ← PARTITION(I’, rows=G, cols=G) |
| L ← ∅; RGBs ← ∅ |
| FOR EACH cell c IN CELLS DO |
| (R, Gc, B) ← MEAN_RGB(c) |
| Y ← 0.2126*R + 0.7152*Gc + 0.0722*B |
| APPEND(L, Y); APPEND(RGBs, (R, Gc, B)) |
| ENDFOR |
| Z ← ZSCORE(L) |
| KEPT ← { i | |Z[i]| ≤ z_thresh } |
| ̅̅̅̅̅̅̅̅R ← MEAN({ RGBs[i].R | i ∈ KEPT }) |
| ̅̅̅̅̅̅̅̅G ← MEAN({ RGBs[i].G | i ∈ KEPT }) |
| ̅̅̅̅̅̅̅B ← MEAN({ RGBs[i].B | i ∈ KEPT }) |
| S ← ̅̅̅̅̅̅̅̅R + ̅̅̅̅̅̅̅̅G + ̅̅̅̅̅̅̅B |
| Rn ← ̅̅̅̅̅̅̅̅R/S; Gn ← ̅̅̅̅̅̅̅̅G/S; Bn ← ̅̅̅̅̅̅̅B/S |
| RETURN f = [̅̅̅̅̅̅̅̅R, ̅̅̅̅̅̅̅̅G, ̅̅̅̅̅̅̅B, Rn, Gn, Bn] |
| ENDPROCEDURE |
| Алгоритм A3. Построение матрицы признаков. |
| PROCEDURE BUILD_FEATURE_MATRIX(df, use_normalized=TRUE) |
| X_raw ← df[R, G, B] AS FLOAT |
| IF use_normalized THEN |
| X_norm ← df[Rn, Gn, Bn] AS FLOAT |
| X ← HSTACK(X_raw, X_norm) |
| feat_names ← [R, G, B, Rn, Gn, Bn] |
| ELSE |
| X ← X_raw |
| feat_names ← [R, G, B] |
| ENDIF |
| y_reg ← df[pH] AS FLOAT |
| y_cls ← df[cls] AS INT |
| RETURN (X, y_reg, y_cls, feat_names) |
| ENDPROCEDURE |
| Алгоритм А4. Кластерный анализ |
| PROCEDURE CLUSTERING_ANALYSIS(X, k_range=1..8, k_opt=3, seed=42) |
| // Step 1: Elbow Method |
| inertias ← ∅ |
| FOR k IN k_range DO |
| km ← KMeans(n_clusters=k, random_state=seed, n_init=10) |
| km.FIT(X[:, 0:3]) // use raw R, G, B only |
| APPEND(inertias, km.inertia_) |
| ENDFOR |
| PLOT_ELBOW(k_range, inertias) |
| // Step 2: Final Clustering with k_opt |
| km_final ← KMeans(n_clusters=k_opt, random_state=seed, n_init=10) |
| labels ← km_final.FIT_PREDICT(X[:, 0:3]) |
| PLOT_3D_SCATTER(X[:, 0:3], color=labels) |
| RETURN labels |
| ENDPROCEDURE |
| Алгоритм A5. Оценка регрессии. |
| PROCEDURE REGRESSION_EVALUATION(X, y_reg, test_ratio=0.20, seed=42) |
| models ← { |
| ’Linear’: LinearRegression(), |
| ’DecisionTree’: DecisionTreeRegressor(seed), |
| ’RandomForest’: RandomForestRegressor(n_estimators=150, max_depth=10, seed), |
| ’SVR’: SVR(kernel=’rbf’, C=1.5) |
| } |
| (X_tr, X_te, y_tr, y_te) ← TRAIN_TEST_SPLIT(X, y_reg, test_ratio, seed) |
| results ← ∅ |
| FOR EACH (name, model) IN models DO |
| model.FIT(X_tr, y_tr) |
| y_pred ← model.PREDICT(X_te) |
| mse ← MEAN_SQUARED_ERROR(y_te, y_pred) |
| rmse ← SQRT(mse) |
| mae ← MEAN_ABSOLUTE_ERROR(y_te, y_pred) |
| r2 ← R2_SCORE(y_te, y_pred) |
| cv_scores ← CROSS_VAL_SCORE(model, X_tr, y_tr, cv=5, scoring=’neg_mse’) |
| cv_mse ← -MEAN(cv_scores) |
| APPEND(results, (name, cv_mse, mse, rmse, mae, r2)) |
| ENDFOR |
| best_model ← SELECT_BY_MAX_R2(results) |
| PLOT_ACTUAL_VS_PREDICTED(y_te, best_model.PREDICT(X_te)) |
| RETURN results |
| ENDPROCEDURE |
| Алгоритм А6. Оценка классификации |
| PROCEDURE CLASSIFICATION_EVALUATION(X, y_cls, test_ratio=0.20, seed=42) |
| models ← { |
| ’KNN’: KNeighborsClassifier(), |
| ’RandomForest’: RandomForestClassifier(n_estimators=150, max_depth=10, seed), |
| ’GradientBoosting’: GradientBoostingClassifier(seed), |
| ’AdaBoost’: AdaBoostClassifier(seed), |
| ’SVM’: SVC(kernel=’rbf’, probability=TRUE, seed) |
| } |
| (Xc_tr, Xc_te, yc_tr, yc_te) ← STRATIFIED_SPLIT(X, y_cls, test_ratio, seed) |
| results ← ∅; conf_matrices ← ∅ |
| FOR EACH (name, model) IN models DO |
| model.FIT(Xc_tr, yc_tr) |
| y_hat ← model.PREDICT(Xc_te) |
| acc ← ACCURACY(yc_te, y_hat) |
| (prec, rec, f1) ← PRECISION_RECALL_F1(yc_te, y_hat, average=’macro’) |
| APPEND(results, (name, acc, prec, rec, f1)) |
| conf_matrices[name] ← CONFUSION_MATRIX(yc_te, y_hat) |
| ENDFOR |
| best_cls ← SELECT_BY_MAX_ACCURACY(results) |
| PLOT_CONFUSION_MATRIX(conf_matrices[best_cls]) |
| RETURN results |
| ENDPROCEDURE |
| Алгоритм A7. Доверительный интервал бутстрапа. |
| PROCEDURE BOOTSTRAP_CI(y_true, y_pred, metric_fn, B=1000, seed=42, alpha=0.05) |
| rng ← RANDOM_GENERATOR(seed) |
| n ← LENGTH(y_true) |
| stats ← ∅ |
| FOR b = 1 TO B DO |
| idx ← rng.INTEGERS(0, n, size=n) // bootstrap resample |
| s ← metric_fn(y_true[idx], y_pred[idx]) |
| APPEND(stats, s) |
| ENDFOR |
| lo ← QUANTILE(stats, alpha / 2) |
| hi ← QUANTILE(stats, 1 - alpha / 2) |
| RETURN (lo, hi) // 95 % confidence interval |
| ENDPROCEDURE |
Литература
- Daniela, L. Pedagogies of Digital Learning in Higher Education; Routledge: London, UK, 2020. [Google Scholar]
- Selwyn, N. Education and Technology: Key Issues and Debates, 3rd ed.; Bloomsbury Academic: London, UK, 2022. [Google Scholar]
- OECD. OECD Digital Education Outlook 2023: Towards an Effective Digital Education Ecosystem; OECD Publishing: Paris, France, 2023. [Google Scholar]
- Steinegger, A.; Wolfbeis, O.S.; Borisov, S.M. Optical sensing and imaging of pH values: Spectroscopies, materials, and applications. Chem. Rev. 2020, 120, 12357–12489. [Google Scholar] [CrossRef]
- Piatkevich, K.D.; Murdock, M.H.; Subach, F.V. Advances in engineering and application of optogenetic indicators for neuroscience. Appl. Sci. 2019, 9, 562. [Google Scholar] [CrossRef]
- Bhatia, D.; Paul, S.; Acharjee, T.; Ramachairy, S.S. Biosensors and their widespread impact on human health. Sens. Int. 2024, 5, 100257. [Google Scholar] [CrossRef]
- Khanal, B.; Pokhrel, P.; Khanal, B.; Giri, B. Machine-learning-assisted analysis of colorimetric assays on paper analytical devices. ACS Omega 2021, 6, 33837–33845. [Google Scholar] [CrossRef]
- Chen, Y.; Fu, Q.; Li, D.; Xie, J.; Ke, D.; Song, Q.; Tang, Y.; Wang, H. A smartphone colorimetric reader integrated with an ambient light sensor and a 3D printed attachment for on-site detection of zearalenone. Anal. Bioanal. Chem. 2017, 409, 6567–6574. [Google Scholar] [CrossRef] [PubMed]
- Soares, S.; Fernandes, G.M.; Rocha, F.R. Smartphone-based digital images in analytical chemistry: Why, when, and how to use. TrAC Trends Anal. Chem. 2023, 168, 117284. [Google Scholar] [CrossRef]
- Das, A.J.; Wahi, A.; Kothari, I.; Raskar, R. Ultra-portable, wireless smartphone spectrometer for rapid, non-destructive testing of fruit ripeness. Sci. Rep. 2016, 6, 32504. [Google Scholar] [CrossRef]
- Pnevmatikakis, E.A.; Giovannucci, A. NoRMCorre: An online algorithm for piecewise rigid motion correction of calcium imaging data. J. Neurosci. Methods 2017, 291, 83–94. [Google Scholar] [CrossRef]
- Apthorpe, N.; Riordan, A.; Aguilar, R.; Homann, J.; Gu, Y.; Tank, D.; Seung, H.S. Automatic neuron detection in calcium imaging data using convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Soltanian-Zadeh, S.; Sahingur, K.; Blau, S.; Gong, Y.; Farsiu, S. Fast and robust active neuron segmentation in two-photon calcium imaging using spatiotemporal deep learning. Proc. Natl. Acad. Sci. USA 2019, 116, 8554–8563. [Google Scholar] [CrossRef] [PubMed]
- Stringer, C.; Pachitariu, M.; Steinmetz, N.; Reddy, C.B.; Carandini, M.; Harris, K.D. Spontaneous behaviors drive multidimensional, brainwide activity. Science 2019, 364, eaav7893. [Google Scholar] [CrossRef]
- Mudanyali, O.; Dimitrov, S.; Sikora, U.; Padmanabhan, S.; Navruz, I.; Ozcan, A. Integrated rapid-diagnostic-test reader platform on a cellphone. Lab. Chip 2012, 12, 2678–2686. [Google Scholar] [CrossRef]
- Contreras, I.; Vehi, J. Artificial intelligence for diabetes management and decision support: Literature review. J. Med. Internet Res. 2018, 20, e10775. [Google Scholar] [CrossRef]
- Sánchez, C.N.; Orvañanos-Guerrero, M.T.; Domínguez-Soberanes, J.; Álvarez-Cisneros, Y.M. Analysis of beef quality according to color changes using computer vision and white-box machine learning techniques. Heliyon 2023, 9, e17976. [Google Scholar] [CrossRef]
- Boppana, N.P.D.; Snow, R.; Simone, P.S.; Emmert, G.L.; Brown, M.A. A low-cost automated titration system for colorimetric endpoint detection. Analyst 2023, 148, 2133–2140. [Google Scholar] [CrossRef]
- Kosenkov, Y.; Kosenkov, D. Computer Vision in Chemistry: Automatic Titration. J. Chem. Educ. 2021, 98, 4067–4073. [Google Scholar] [CrossRef]
- Parakh, A.; Awate, A.; Barman, S.M.; Kadu, R.K.; Tulaskar, D.P.; Kulkarni, M.B.; Bhaiyya, M. Artificial intelligence and machine learning for colorimetric detections: Techniques, applications, and future prospects. Trends Environ. Anal. Chem. 2025, 48, e00280. [Google Scholar] [CrossRef]
- Li, Y.; Dutta, B.; Yeow, Q.J.; Clowes, R.; Boott, C.E.; Cooper, A.I. High-throughput robotic colourimetric titrations using computer vision. Digit. Discov. 2025, 4, 1276–1283. [Google Scholar] [CrossRef]
- Craig, R.L.; Peterson, P.K.; Nandy, L.; Lei, Z.; Hossain, M.A.; Camarena, S.; Dodson, R.A.; Cook, R.D.; Dutcher, C.S.; Ault, A.P. Direct Determination of Aerosol pH: Size-Resolved Measurements. Anal. Chem. 2018, 90, 11232–11239. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Su, H.; Ma, N.; Zheng, G.; Kuhn, U.; Li, M.; Klimach, T.; Pöschl, U.; Cheng, Y. Multifactor colorimetric analysis on pH-indicator papers: An optimized approach for direct determination of ambient aerosol pH. Atmos. Meas. Tech. Discuss. 2020, 13, 6053–6065. [Google Scholar] [CrossRef]
- Elsenety, M.M.; Mohamed, M.B.I.; Sultan, M.E.; Elsayed, B.A. Facile and highly precise pH-value estimation using common pH paper based on machine learning techniques and supported mobile devices. Sci. Rep. 2022, 12, 22584. [Google Scholar] [CrossRef]
- Hou, H.; Zhao, Y.; Li, C.; Wang, M.; Xu, X.; Jin, Y. Single-cell pH imaging and detection for pH profiling and label-free rapid identification of cancer-cells. Sci. Rep. 2017, 7, 1759. [Google Scholar] [CrossRef]
- Prakash, D.C.; Narayanan, R.; Ganesh, N.; Ramachandran, M.; Chinnasami, S.; Rajeshwari, R. A study on image processing with data analysis. AIP Conf. Proc. 2022, 2393, 020225. [Google Scholar]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Raschka, S.; Liu, Y.H.; Mirjalili, V. Machine Learning with PyTorch and Scikit-Learn; Packt Publishing: Birmingham, UK, 2022. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R.; Taylor, J. Statistical Learning. In An Introduction to Statistical Learning: With Applications in Python; Springer: Berlin/Heidelberg, Germany, 2023; pp. 15–67. [Google Scholar]
- Subramanya, S.M.; Rios, N.; Kollar, A.; Stofanak, R.; Maloney, K.; Waltz, K.; Powers, L.; Rane, C.; Savage, P.E. Statistical models for predicting oil composition from hydrothermal liquefaction of biomass. Energy Fuels 2023, 37, 6619–6628. [Google Scholar] [CrossRef]
- Lafuente, D.; Cohen, B.; Fiorini, G.; García, A.A.; Bringas, M.; Morzan, E.; Onna, D. A gentle introduction to machine learning for chemists: An undergraduate workshop using Python notebooks for visualization, data processing, analysis, and modeling. J. Chem. Educ. 2021, 98, 2892–2898. [Google Scholar] [CrossRef]
- Hodson, T.O. Root-mean-square error (RMSE) or mean absolute error (MAE): When to use them or not. Geosci. Model Dev. 2022, 15, 5481–5487. [Google Scholar] [CrossRef]
- Müller, A.C.; Guido, S. Introduction to Machine Learning with Python: A Guide for Data Scientists; O’Reilly Media: Sebastopol, CA, USA, 2016. [Google Scholar]
- Cunningham, P.; Delany, S.J. K-nearest neighbour classifiers—A tutorial. ACM Comput. Surv. 2021, 54, 128. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Sri Sruthi, P.; Balasubramanian, S.; Senthil Kumar, P.; Kapoor, A.; Ponnuchamy, M.; Mariam Jacob, M.; Prabhakar, S. Eco-friendly pH detecting paper-based analytical device: Towards process intensification. Anal. Chim. Acta 2021, 1182, 338953. [Google Scholar] [CrossRef] [PubMed]
- Pastore, A.; Badocco, D.; Bogialli, S.; Cappellin, L.; Pastore, P. pH Colorimetric Sensor Arrays: Role of the color space adopted for the calculation of the prediction error. Sensors 2020, 20, 6036. [Google Scholar] [CrossRef]
Авторы: In-Seong Jeon, Sukjae Joshua Kang, Chan-Woung Jeong, Seunghyeon Kim, Seong-Joo Kang


